在Linux系统下,使用 less 命令能较好查看文件内容,使用 vim 命令能编辑文件内容。它们都适用于对大文件内容的查看和编辑。
而在Windows系统下,使用记事本或notepad++等软件仅能对小文件内容进行查看和编辑。若需要对大文件内容进行查看和编辑,推荐使用EmEditor或PilotEdit软件。

第一种方法:批量化使用smartctl命令检测CEPH系统中机械硬盘的信息,确定有坏道磁盘的SN编号,或留取正常磁盘的SN编号。
第二种方法:在CEPH网页管理界面的OSD栏目中搜索关键词down,检测对应OSD的编号、磁盘SN编号和磁盘在Linux系统中的识别名称,如下图所示。
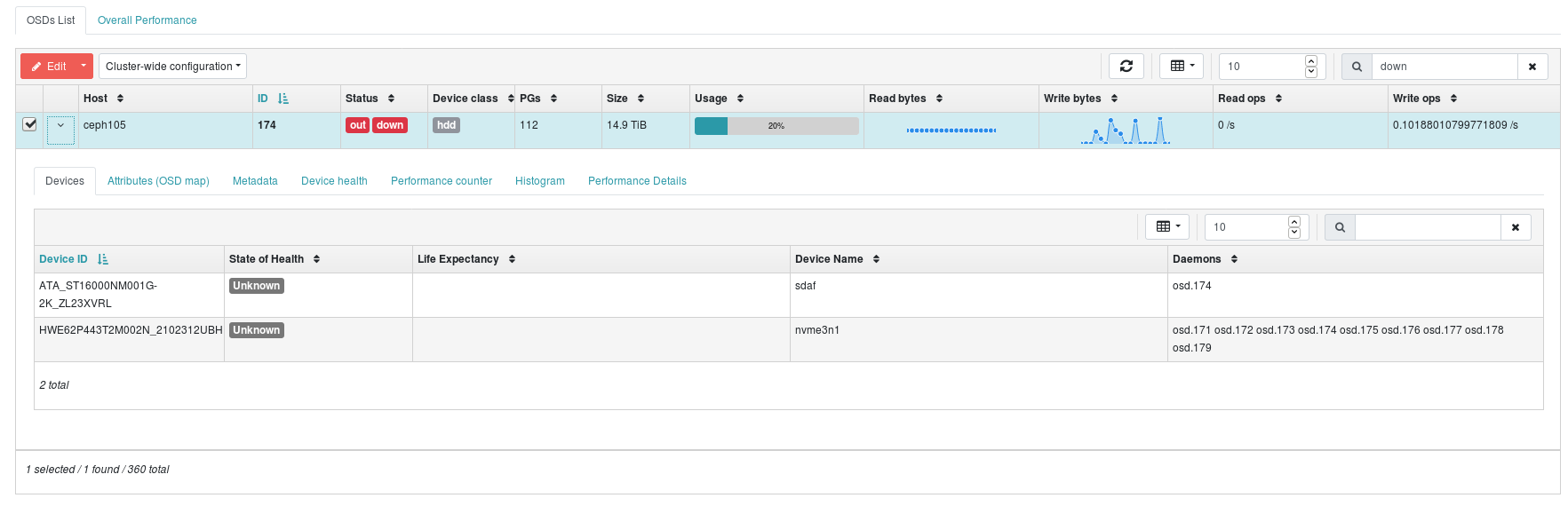
以上示例中找到的损坏磁盘关键信息:
磁盘对应的OSD编号:osd.174 后续需要删除并重建该osd编号。 磁盘SN编号:ZL23XVRL 有利于拔下有问题的硬盘,以免拔错。 Linux下的磁盘识别名称:sdaf 加上新盘后,需要对该盘进行分区操作。
在计算服务器上卸载CEPH文件系统(可选)。我这边由于需要通过一台登录节点服务器作为中转,再登录CEPH服务器进行操作。因此,该登录节点服务器需要卸载 CEPH文件系统,以免CEPH文件系统掉线后,无法登录该服务器。
for i in 1 2 11 12 13 14 15 16 17 18 19 20
do
echo "ssh node$i sudo umount -l /ceph"
done > command.umount.list
ParaFly -c command.umount.list -CPU 12
通过指令暂停CEPH系统:
ceph osd set noout
ceph osd set norecover
ceph osd set norebalance
ceph osd set nobackfill
ceph osd set nodown
ceph osd set pause
再关闭所有CEPH服务器或仅关闭有坏道的CEPH存储服务器的Linux系统。本次是在ceph105机器上发现有坏盘,对该机器关机并更换硬盘后手动启动,其它存储服务器重启。
echo "ssh ceph110 sudo shutdown -r now
ssh ceph109 sudo shutdown -r now
ssh ceph108 sudo shutdown -r now
ssh ceph107 sudo shutdown -r now
ssh ceph106 sudo shutdown -r now
ssh ceph105 sudo shutdown -h now
ssh ceph104 sudo shutdown -r now
ssh ceph103 sudo shutdown -r now
ssh ceph102 sudo shutdown -r now" > command.shutdown.list
ParaFly -c command.shutdown.list -CPU 9
ssh ceph101 sudo shutdown -r now重启CEPH集群后,进行时间同步、网络优化和CEPH参数优化。
for ((i=102;i<=110;i=i+1))
do
echo "ssh ceph$i ntpdate ceph101"
done > command.ntpdate.list
ParaFly -c command.ntpdate.list -CPU 9
for ((i=102;i<=110;i=i+1))
do
echo "ssh ceph$i systemctl restart chronyd.service"
done > command.chronyd.list
ParaFly -c command.chronyd.list -CPU 9
for ((i=102;i<=110;i=i+1))
do
echo "ssh ceph$i /root/bin/rc.local"
done > command.rc_local.list
ParaFly -c command.rc_local.list -CPU 9
/root/bin/rc.local
for ((i=102;i<=110;i=i+1))
do
echo "ssh ceph$i /root/bin/ethtool_lro.sh"
done > command.ethtool_lro.list
ParaFly -c command.ethtool_lro.list -CPU 9
/root/bin/ethtool_lro.sh
for ((i=102;i<=110;i=i+1))
do
echo "ssh ceph$i /root/bin/test.sh"
done > command.ethtool_test.list
ParaFly -c command.ethtool_test.list -CPU 9
/root/bin/test.sh
for ((i=101;i<=110;i=i+1))
do
echo "ssh ceph$i /root/bin/modifing_OSD_parameters.pl 22 8 true 10 86400 604800 0.5 0.05 259200 100 10 10 100"
done > command.modifing_OSD_parameters.list
ParaFly -c command.modifing_OSD_parameters.list -CPU 10
ceph config set mds mds_log_max_segments 1024
ceph config set mds mds_cache_trim_threshold 25600000
ceph config set mds mds_cache_trim_decay_rate 0.01
ceph config dump
取消CEPH系统的暂停操作:
ceph osd set noout
ceph osd set norecover
ceph osd set norebalance
ceph osd set nobackfill
ceph osd set nodown
ceph osd set pause
给CEPH存储服务器添加虚拟内存(可选)。我管理的CEPH存储服务器每个节点内存为256 GiB,在MDS服务器上可能不够,给每台服务器再添加256G SWAP空间。
for ((i=101;i<=110;i=i+1))
do
echo "ssh ceph$i swapon /swapadd"
done > command.swapon.list
ParaFly -c command.swapon.list -CPU 10
在更换了坏盘的ceph105主机上进行新盘的分区操作。
根据最开始安装CEPH系统时留下的磁盘分区的操作记录信息,对新加入的磁盘进行相同的分区操作。首先,使用新加入的磁盘,添加到一个新的虚拟盘中。
vgcreate ceph-block-31 /dev/sdaf然后,对虚拟盘进行分区。
lvcreate -l 100%FREE -n block-31 ceph-block-31以上命令需要确定新加入磁盘对应的Linux识别编号和虚拟盘编号,是操作的成败关键。
由于新加入的盘替换了坏盘的位置,重启服务器后,其Linux识别编号不变。若采用不关停CEPH系统直接更换硬盘的话,则热插拔更换硬盘后,其Linux识别编号在所有磁盘识别编号往后计数,和坏盘之前的编号不一致。
由于最初安装CEPH系统时,直接使用了ceph-block-num的虚拟盘分区名称。若此时未保留最初的磁盘分区命令,可以使用lvdisplay查看系统中的虚拟盘分区(也称为逻辑卷)信息,查看缺失的逻辑卷名称。
lvdisplay | grep " LV Name" | grep block | sort
lvdisplay | grep " VG Name" | grep block | sort删除OSD编号:
ceph auth del osd.174
ceph osd crush remove osd.174
ceph osd rm 174根据最开始安装CEPH系统时留下的OSD创建记录,将新的虚拟盘分区创建成OSD。由于使用了bluestore的方法,一个OSD包含一个完整物理磁盘做的逻辑卷和一块固态硬盘部分扇区做的逻辑卷。后者的逻辑卷名称不能搞错,因此该步骤一定要有最初安装CEPH系统时留下的OSD创建记录。
ceph-volume lvm create --bluestore --data ceph-block-31/block-31 --block.db ceph-db-4/db-31以上步骤会自动分配一个新的OSD编号。CEPH系统应该是自动按照数字编号往后进行OSD编号分配。由于刚删除了一个编号,新的自动分配的编号就刚好是删除的OSD编号。
新的OSD上线后,数据会自动进行重新分配(rebalancing),结束后CEPH恢复健康状态。
[root@ceph101 ~]# ceph -s
cluster:
id: 8f1c1f24-59b1-11eb-aeb6-f4b78d05bf17
health: HEALTH_WARN
Slow OSD heartbeats on back (longest 23249.475ms)
Slow OSD heartbeats on front (longest 23245.394ms)
services:
mon: 5 daemons, quorum ceph101,ceph103,ceph107,ceph109,ceph105 (age 21m)
mgr: ceph107.gtrmmh(active, since 22m), standbys: ceph101.qpghiy
mds: cephfs:3 {0=cephfs.ceph108.iuobhj=up:active,1=cephfs.ceph102.imxzno=up:active,2=cephfs.ceph104.zhkcjt=up:active} 1 up:standby
osd: 360 osds: 360 up (since 17m), 360 in (since 17m); 47 remapped pgs
data:
pools: 4 pools, 10273 pgs
objects: 386.82M objects, 657 TiB
usage: 1.2 PiB used, 4.0 PiB / 5.2 PiB avail
pgs: 8742316/3849861458 objects misplaced (0.227%)
10220 active+clean
47 active+remapped+backfilling
6 active+clean+scrubbing+deep
io:
client: 3.4 MiB/s rd, 392 MiB/s wr, 6 op/s rd, 221 op/s wr
recovery: 181 MiB/s, 103 objects/s
progress:
Rebalancing after osd.174 marked in (17m)
[=======.....................] (remaining: 44m)
在CEPH系统的MDS服务中,文件系统的元数据以日志形式存放于segment中,每个sgement存放1024个操作记录。当文件系统的数据使用完毕,CEPH系统则会以一定的速度Trim (消除) 元数据信息,此时会将MDS服务器中的数据回写到CEPH的磁盘OSD中,以降低MDS服务器上运行的mds服务的内存消耗。当segment数量超过默认128个时,则CEPH报警,意味着MDS服务器中保存了过量的元数据信息,占用内存可能较多,需要及时注意。
[root@ceph101 ~]# ceph health detail
HEALTH_WARN 2 MDSs behind on trimming
[WRN] MDS_TRIM: 2 MDSs behind on trimming
mds.cephfs.ceph102.imxzno(mds.1): Behind on trimming (2235/128) max_segments: 128, num_segments: 2235
mds.cephfs.ceph106.hggsge(mds.2): Behind on trimming (4260/128) max_segments: 128, num_segments: 4260
当遇到以上警告,若发现MDS服务器的内存足够,可以将默认阈值128提高,或加大Trim速度。
通过设置mds_log_max_segments参数来提高CEPH的 max_segments 数,在CEPH系统任意主机上运行即可。
ceph config set mds mds_log_max_segments 1024通过设置参数来提升Trim速度。CEPH系统根据mds_cache_trim_threshold (默认256Ki)和mds_cache_trim_decay_rate (默认1.0)两个参数设置sgements的消除速度。默认设置下,当CEPH系统进行持续且Trim速度达到最大时,每秒钟Trim的记录数量为 ln(0.5)/rate*threshold 。当在CEPH系统中并行化读取或写入文件时,短时间内进行大量的文件操作,极容易导致segments过多,无法及时Trim。因此,需要提高Trim速度,其实也消耗不了太多CPU资源。
mds_cache_trim_threshold 设置了一定时间内能消除的最大文件数量。在进行Trim时,CEPH系统中有一个Counter程序记录了一定时间内被消除的文件数量。mds_cache_trim_decay_rate 参数和Counter程序的半衰期相关,该值越小,则半衰期越短。
默认参数值过于保守,下当为了提高Trim速度,推荐将 mds_cache_trim_threshold 参数提升到100倍,将mds_cache_trim_decay_rate参数降低到100倍。在任意一台CEPH主机中运行命令:
ceph config set mds mds_cache_trim_threshold 25600000
ceph config set mds mds_cache_trim_decay_rate 0.01对PG进行Scrub,即检测PG分布到各OSDs上的数据是否一致。包含两种算法:第一种为Scrub,即仅检测数据的元信息,例如时间戳和文件大小等信息,速度快且基本不消耗磁盘;第二种为deep Scrub,会额外检测数据的内容是否一致,速度较慢且消耗大量磁盘读取。在CEPH系统进行scrub和deep-scrub的主要参数为:
(1)osd_scrub_begin_hour:设置进行Scrub的起始时间,推荐设置为22,即在晚上10点开始进行Scrub。CEPH系统默认值是0。 (2)osd_scrub_end_hour:设置进行Scrub的结束时间,推荐设置为8,即在早上8点结束scrub。CEPH系统默认值是24。 (3)osd_scrub_auto_repair:设置发现PG在多个OSDs中的数据不一致后,是否进行修复,推荐设置为true,即表示自动进行修复。CEPH系统默认值为false。 (4)osd_max_scrubs:进行Scrub时,设置单个OSD能同时进行Scrub操作数,推荐设置为10。CEPH系统默认值是1,会导致整个系统能同时进行的Scrub操作数很少。提高该值能明显增加Scrub的并行数,增加Scrub速度。否则,可能导致pgs not deep-scrubbed in time的警报。 (5)osd_scrub_min_interval:设置单个PG进行Scrub的最小间隔时间,默认值为86400,一天。 (6)osd_scrub_max_interval:设置单个PG进行Scrub的最大间隔时间,默认值为604800,一周。 (7)osd_scrub_interval_randomize_ratio:设置单个PG进行Scrub时,间隔会额外增加一定的随机时间,该时间为osd_scrub_min_interval*该阈值,默认值为0.5。 (8)osd_deep_scrub_randomize_ratio:在进行Scrub时,随机变更为deep scrub的概率,推荐设置为0.05。CEPH系统默认值为0.15。 (9)osd_deep_scrub_interval:设置进行deep Scrub的时间间隔,推荐设置为259200,即一月30天。CEPH系统默认值为604800,即若有PG没能在一周内进行deep scrub,则导致pgs not deep-scrubbed in time的警报。改变该值应该并不能减慢或加快deep scrub的速度。
以上参数表示:对每个PG进行清理,每隔1~1.5天即会进行一次Scrub。每次进行Scrub时,有5%的概率变更为deep scrub,这表示平均20~30天会对所有PGs进行一轮deep Scrub。当一个星期后,若有PG未进行scrub,或一个月后,若有PG未进行deep-scrub,则进行报警。进行优化方式:通过增大 osd_max_scrubs 参数值来加快scrub速度;通过减少 osd_deep_scrub_randomize_ratio 参数值来减少deep scrub任务量,减少对磁盘的读取消耗。
当CEPH系统更换硬盘时,会将一些PGs转移到新硬盘做的OSD上,这时需要对数据进行回填。默认情况下,回填速度极慢,需要修改OSD参数增加回填速度。
(10)osd_max_backfills:设置CEPH系统一次最多对指定数量的PGs进行回填,推荐根据需要回填的PGs数量和CEPH系统的整体OSDs数量来设置。默认值为1,过小,会导致回填速度极慢,可能需要数天才能让数据修复完毕。咱们系统有一次更换硬盘后需要对66个PGs进行回填,我直接设置该值为66即可。推荐该值 * PG副本数 / OSDs总数 不要超过 3,即让每个硬盘同时的读和写并发不要过大。 (11)osd_recovery_max_active:进行数据恢复时,设置每个OSD的最大读写请求数,推荐设置为10。CEPH系统默认值为3。 (12)osd_recovery_max_active_hdd:进行数据恢复时,设置每个OSD的机械硬盘最大读写请求数,推荐设置为10。CEPH系统默认值为3。 (13)osd_recovery_max_active_ssd:进行数据恢复时,设置每个OSD的固态硬盘最大读写请求数,推荐设置为100。CEPH系统默认值为10。
需要在各台CEPH存储服务器上运行程序,对各自的OSDs进行参数修改。且通过命令行修改仅在当前CEPH系统中生效,重启服务器后失效。
ceph tell osd.0 injectargs --osd_scrub_begin_hour=22 --osd_scrub_end_hour=8 --osd_scrub_auto_repair=true --osd_max_scrubs=10 --osd_scrub_min_interval=86400 --osd_scrub_max_interval=604800 --osd_scrub_interval_randomize_ratio=0.5 --osd_deep_scrub_randomize_ratio=0.05 --osd_deep_scrub_interval=259200 --osd_max_backfills=100 --osd_recovery_max_active=10 --osd_recovery_max_active_hdd=10 --osd_recovery_max_active_ssd=100查看修改后的参数结果:
ceph daemon osd.0 config show | egrep "osd_scrub_begin_hour|osd_scrub_end_hour|osd_scrub_auto_repair|osd_max_scrubs|osd_scrub_min_interval|osd_scrub_max_interval|osd_scrub_interval_randomize_ratio|osd_deep_scrub_randomize_ratio|osd_deep_scrub_interval|osd_max_backfills|osd_recovery_max_active|osd_recovery_max_active_hdd|osd_recovery_max_active_ssd"CEPH会定期(默认每个星期一次)对所有的PGs进行scrub,即通过检测PG中各个osds中数据是否一致来保证数据的安全。
当CEPH更换一块坏硬盘,进行数据修复后,出现了大量的PGs不能及时进行scrub,甚至有些PGs数据不一致,导致CEPH系统报警,如下所示:
cluster:
id: 8f1c1f24-59b1-11eb-aeb6-f4b78d05bf17
health: HEALTH_ERR
6 scrub errors
Possible data damage: 5 pgs inconsistent
1497 pgs not deep-scrubbed in time
1466 pgs not scrubbed in time
services:
mon: 5 daemons, quorum ceph101,ceph103,ceph107,ceph109,ceph105 (age 5d)
mgr: ceph107.gtrmmh(active, since 9d), standbys: ceph101.qpghiy
mds: cephfs:3 {0=cephfs.ceph106.hggsge=up:active,1=cephfs.ceph104.zhkcjt=up:active,2=cephfs.ceph102.imxzno=up:active} 1 up:standby
osd: 360 osds: 360 up (since 5d), 360 in (since 5d)
data:
pools: 4 pools, 10273 pgs
objects: 331.80M objects, 560 TiB
usage: 1.1 PiB used, 4.2 PiB / 5.2 PiB avail
pgs: 10261 active+clean
7 active+clean+scrubbing+deep
5 active+clean+inconsistent
io:
client: 223 MiB/s rd, 38 MiB/s wr, 80 op/s rd, 12 op/s wr
此时,需要提高对PGs的scrub速度。默认情况下一个OSD近能同时进行一个scrub操作且仅当主机低于0.5时才进行scrub操作。我运维的CEPH系统一个PG对应10个OSDs,每个OSD仅能同时进行一个scrub操作,导致大量scrub操作需要等待,而同时进行的scrub操作数量一般为8个。因此需要在各台存储服务器上对其OSDs进行参数修改,来提高scrub速度。
osd_max_scrubs参数用于设置单个OSD同时进行的最大scrub操作数量;osd_scrub_load参数设置负载阈值。主要修改以上两个参数来提高scrub速度,其默认值为1和0.5。
例如,对ceph101主机中的所有OSDs进行参数修改:
首先,获取ceph101中所有的OSD信息:
ceph osd dump | grep `grep ceph101 /etc/hosts | perl -ne 'print $1 if m/(\d\S*)/'` | perl -ne 'print "$1\n" if m/(osd.\d+)/' > /tmp/osd.list
然后,对所有OSD的参数进行批量修改:
for i in `cat /tmp/osd.list`
do
ceph tell $i injectargs --osd_max_scrubs=10 --osd_scrub_load_threshold=10
done检查修改后的效果
for i in `cat /tmp/osd.list`
do
echo $i
ceph daemon $i config show | egrep "osd_max_scrubs|osd_scrub_load"
done
对所有的CEPH主机进行上述修改后,同时进行scrub的数量提高了30倍,并且使用top命令可以看到ceph-osd进程对CPU的资源消耗明显上升。
cluster:
id: 8f1c1f24-59b1-11eb-aeb6-f4b78d05bf17
health: HEALTH_ERR
6 scrub errors
Possible data damage: 5 pgs inconsistent
1285 pgs not deep-scrubbed in time
1208 pgs not scrubbed in time
1 slow ops, oldest one blocked for 37 sec, daemons [osd.124,osd.352] have slow ops.
services:
mon: 5 daemons, quorum ceph101,ceph103,ceph107,ceph109,ceph105 (age 5d)
mgr: ceph107.gtrmmh(active, since 9d), standbys: ceph101.qpghiy
mds: cephfs:3 {0=cephfs.ceph106.hggsge=up:active,1=cephfs.ceph104.zhkcjt=up:active,2=cephfs.ceph102.imxzno=up:active} 1 up:standby
osd: 360 osds: 360 up (since 5d), 360 in (since 5d)
data:
pools: 4 pools, 10273 pgs
objects: 331.80M objects, 560 TiB
usage: 1.1 PiB used, 4.2 PiB / 5.2 PiB avail
pgs: 10041 active+clean
152 active+clean+scrubbing+deep
75 active+clean+scrubbing
3 active+clean+scrubbing+deep+inconsistent+repair
2 active+clean+inconsistent
io:
client: 65 MiB/s rd, 4.2 MiB/s wr, 21 op/s rd, 2 op/s wr
此外,注意:(1)提高scrub的并行数可能对CEPH集群内网的网速要求较高,推荐使用10GE以上交换机。(2)条scrub的并行数,会导致一个OSD对应的硬盘同时并行读取的操作数量较高,当导致磁盘100%被使用时,可能磁盘的利用效率并不高,因此不推荐将 osd_max_scrubs参数调节到10以上。
对两个星期内(当前时间2022-08-03)未进行deep-scrubbed,已经有报警信息的PGs进行操作。
ceph pg dump | perl -e 'while (<>) { @_ = split /\s+/; $pg{$_[0]} = $1 if ($_[22] =~ m/2022-07-(\d+)/ && $1 <= 21); } foreach ( sort {$pg{$a} <=> $pg{$b}} keys %pg ) { print "ceph pg deep-scrub $_; sleep 30;\n"; }' > for_deep_scrub.list
sh for_deep_scrub.list
在官网下载RStudio的rmp安装包并进行安装。以CentOS8系统为例:
wget https://download2.rstudio.org/server/rhel8/x86_64/rstudio-server-rhel-2022.07.1-554-x86_64.rpm
sudo yum install rstudio-server-rhel-2022.07.1-554-x86_64.rpmdnf -y install readline readline-devel libcurl libcurl-devel gcc-gfortran libXt* readline* bzip2* xz* pcre* curl-devel *ltdl* libpng-devel libtiff-devel libjpeg-turbo-devel pango-devel libpng-devel
wget https://cran.r-project.org/src/base/R-4/R-4.2.1.tar.gz
tar zxf R-4.2.1.tar.gz
cd R-4.2.1/
./configure --prefix=/opt/sysoft/R-4.2.1 --enable-R-shlib --with-tcltk
make -j 8
make install
ln -s /opt/sysoft/R-4.2.1/bin/* /usr/bin/
firewall-cmd --add-port=8787/tcp --permanent
firewall-cmd --reload
systemctl restart rstudio-server.service
systemctl enable rstudio-server.service
在浏览器中访问 IP:8787,再输入系统用户和密码登录即可。
高级用法:可以通过修改配置文件/etc/rstudio/rserver.conf来指定RStudio使用的R命令和相应端口。例如:
rsession-which-r=/opt/sysoft/R-4.2.1/bin/R www-port=8787
在Linux系统中输入命令,当命令后输入的字符数量超过阈值时,会导致程序运行失败,出现提示:argument list too long。常见于rm、ls、cp、mv和tar等命令对大量文件进行处理时。
ARG_MAX(maximum length of arguments for a new process)参数用来设置进程的参数字符长度。
# getconf ARG_MAX
2621440
# ulimit -s
10240
前者是命令后输入的字符数2.6M。后者设置堆栈空间大小,单位是KiB,该值 * 1024 / 4 = 前者。通过ulimit命令提高 ARG_MAX 阈值。
# ulimit -s 102400
# getconf ARG_MAX
26214400修改配置文件/etc/security/limits.conf,设置limits参数:
# cat <<EOF >> /etc/security/limits.conf
* soft nproc 10240
* hard nproc 102400
* soft nofile 10240
* hard nofile 102400
* soft stack 10240
* hard stack 102400
EOF使用perl循环删除文件
# perl -e 'while (<*key_word*>) { print "rm -rf $_\n"; }' | sh得到文件列表后,tar命令使用参数-T输入列表文件进行打包
# perl -e 'while (<*key_word*>) { print "$_\n"; }' > file.list
# tar zcf file.tar.gz -T file.list
(1)打开网站https://hiplot.com.cn/basic/bubble,导入GO气泡图的数据文件,推荐使用纯文本文件,内容示例如下:
Term Count Ratio PValue
GO:0046873~metal ion transmembrane transporter activity 25 0.0399361022364217 0.00001043522
GO:0098655~cation transmembrane transport 33 0.0527156549520767 0.00001818934
GO:0006812~cation transport 42 0.0670926517571885 0.00001818934
GO:0006811~ion transport 56 0.0894568690095847 0.00001818934
若表头和上述示例不一致,则需要再导入按钮下方的四个选择框中浏览对应的数据列。
(2)在设置参数处,设置参数:Title填入相应的标题信息;Image Export选择pdf和svg;Width选择10,height选择8,这两者用于设置整个图片的宽度和高度;点击向下的三箭头图标,打开更多参数设置;Title Size设置14,Legend Title Size设置12;Legend Text Siz设置12;Axis Title Size设置14;Axis Font Size设置12;Show Top Items设置20;注意设置Legend of Transformed Color为FDR;推荐设置Show Percent(X ais)。
(3)最后提交,会看到结果,再下载图片。
藏龙岛国家级湿地公园规划面积为401公顷,位于江夏区藏龙岛科技园,包括杨桥湖、上潭湖、下潭湖、玉叶滩、明星林场等区域,有“藏龙八景”、“杨桥湖二十四桥”等景观。园区生活着黑斑蛙、中华大蟾蜍、乌梢蛇、豹猫等省级保护动物,八哥、家燕、黑水鸡、灰喜鹊、大山雀等省级保护鸟类。
园区生活着黑斑蛙、中华大蟾蜍、乌梢蛇、豹猫等省级保护动物,八哥、家燕、黑水鸡、灰喜鹊、大山雀等省级保护鸟类。
2011年1月,武汉市新添两个省级湿地公园——后官湖湿地公园和藏龙岛湿地公园。至此,武汉市省级湿地公园达3个。 武汉已建有东湖国家湿地公园,以及杜公湖、后官湖、藏龙岛等3个省级湿地公园,总面积为5207.3公顷。藏龙岛湿地公园拟用8年建设,由武汉江夏经济开发区藏龙岛办事处承建,规划投资1.5亿多元。2013年4月份藏龙岛省级湿地公园升级为国家湿地公园,与东湖比肩,将按高标准进行植被恢复等保护性建设。
藏龙岛湿地公园主要建设内容为喷泉景观改造工程、芦苇荡建设和改造工程、驳岸改造工程、码头建设和服务中心改造工程、新建鱼鲜饮食街、高尔夫球场堤坝景观改造工程、藏龙号周边景观改造和地标性水景建设、玉叶滩开发及明星林场改造工程、桥梁重建及藏龙号广场建设等工程。
后官湖湿地公园是国家级湿地公园,面积达3186.3公顷,是东湖湿地公园的3倍,为武汉建设的最大的湿地公园。位于三环线以西、蔡甸中北部,包括百镰湖、皮泗湖、筲箕湖、王家湖、高湖、知音湖及沿岸用地。该湿地公园建成后,将再现“青山隐隐曲水绕,草滩深处白鹭飞”的原生态自然景观。
后官湖绿道位于武汉市蔡甸区后官湖畔。总长度110公里 ,占地总面积约530公顷 ,带有骑行专用自行车道和步道,是武汉首条郊野绿道,也是全国第二条郊野绿道。
后官湖湿地公园位于蔡甸区中北部,高湖水域沿岸,地理坐标为:东经113°58′-114°05′,北纬30°30′-30°34′之间。区域内山水资源丰富,属浅水型淡水湖泊,具有底平、水浅、水生生物资源丰富、湖泊功能显著等特征。
后官湖主体由知音湖、皮泗海、白莲湖、天鹅湖、高湖组成。区域内自然形成的岬、屿、岛、湾、洲星罗棋布,湖泊岸线自然曲折,湖光山色交相辉映,既有完整的湿地生态系统,又有湖区渔耕的人文风貌。
公园内风光旖旎,群山环绕,俊俏靓丽,主要包括玉笋山、横山、马鞍山、笔架山、天子山、伏牛山、凤凰山等十多座山。区域内最高景观眺望点是马鞍山,高程为88.3米。临近后官湖南岸的天子山,高程为66.5米,是最佳观园赏景视点。
后官湖属于属亚热带过渡性季风气候,具有热丰、水富、光足的特点。
后官湖湿地生物多样性丰富,动植物种类繁多。共有维管束植物69科,131属,158种,其中有国家重点保护野生植物莲和野菱2种。有脊椎动物33目81科258种,其中,鱼类8目15科80种,两栖动物1目4科10种,爬行动物2目7科24种,鸟类15目43科149种,兽类7目12科23种。在258种脊椎动物中,国家重点保护动物24种,其中,国家Ⅰ级有白头鹤1种,Ⅱ级有河麂、白琵鹭、灰鹤、黑鸢、赤腹鹰、普通鵟、红角鸮、斑头鸺鹠等23种。有浮游藻类7门30科52属78种,浮游动物20种,底栖动物42种。优越的自然地理环境,使后官湖湿地成为大武汉不可多得的一个天然野生动植物园。
2010年,武汉市将后官湖列入新建湿地公园的行列。同年,湖北省林业厅以鄂林护函〔2010〕545号文件批准建立后官湖省级湿地公园。为了进一步加强后官湖湿地公园的建设和管理,2012年,蔡甸区委区政府决定,将后官湖湿地申报为国家湿地公园。湖北省野生动植物保护总站、中国科学院武汉植物园等单位专家对后官湖湿地公园本底资源进行了系统调查,在此基础上,编制了总体规划。 后官湖湿地公园拟用8年建设,由武汉蔡甸现代农业投资有限公司承建,规划投资4.44亿多元。
国家林业局发布了2016年试点国家湿地公园验收结果:蔡甸区后官湖国家湿地公园(试点)顺利通过验收,正式成为“国家湿地公园”。
有人说,因为湖水的形状像“官”字而得名。
也有人说,因为姜子牙的传说而得名“候官湖”。
相传,姜子牙年轻时文武双全,武功盖世,但生不逢时,一直没得到朝廷重用。47岁那年,天下大旱,父亲为寻水源劳累而死,母亲也奄奄一息。姜子牙背着母亲一边乞讨,一边寻找水源。
终于,母子俩找到蔡甸的一个大湖,并在湖边定居下来,靠砍柴捕鱼苦度生计。这天,来了一位脚穿草鞋、头戴破帽的乞讨老人,姜母见其可怜,毫不犹豫将自家仅有一块面饼递给老人。老人说,“我家还有老伴重病在床,请你们帮帮忙,送我老伴去治病,你们望着北极星向北翻过三座山就到了。”
次日,姜子牙翻过三座山,看到一座宫殿。从宫殿中走出一人,原来就是昨天乞讨的那位老人。经过老人举荐,姜子牙在朝庭做了官。后来,姜子牙封官为侯,先后辅佐六位周王。因此,当地人将他出仕前生活过的那片大湖叫“候官湖”。凡蔡甸地区学子进京赶考,必得从候官湖走水路去汉口。而京城放榜的喜讯,从京城传到汉口,也再沿水路传到蔡甸。那些一心想走仕途的学子们,常常会在京城放榜之日,站在候官湖畔等待喜讯。
大家干脆将这片湖称为“候官湖”,后来口口相传,就演变成“后官湖”。
“自古以来,许多朝代的名人高官都诞生于这片湖区,如明代兵部尚书戴金,清康熙帝师熊伯龙等,因此民间还有一种说法,古时候蔡甸地区的学子进京赶考,必得从今天的后官湖畔走水路先往武昌,再去京城,而京城放榜的日子,喜报也会沿水路传到蔡甸。于是,那些一心想走仕途的学子们,常常会在京城放榜的日子里,站在湖畔等候京官送来喜报”。
这种说法在普通老百姓那里的另一个理解是,这些在此等候的人,从此之后便为官人了,而且“候”和“后”同音,所以渐渐把这个地方叫作“后官湖”。
王汉伟介绍,在蔡甸古地方志里,有关后官湖的记载,一直有“候官湖”和“后官湖”两种提法,但“后官湖”的提法居多,后来约定俗成,使用了“后官湖”。
王汉伟感慨,20多年前,大后官湖水域还是一片“野湖汊”,伴随着国家级经济开发区沌口车都的打造,汉阳王家湾的崛起,汉阳黄金口工业园的建设,经开区城市化进程等,如今环湖四周已形成现代工业集聚区和都市生活居住区相融合的“产城一体”城市格局。而随着城市化进程,以前湖汊众多的后官湖,已成为大水网,使武汉西部的后官湖,一跃成为武汉境内的第四大湖。
后官湖绿道所经之地有亮丽的湖光山色、丰富的人文景观、充满活力的玩乐项目。据了解,后官湖郊野绿道将生态资源保护和知音文化传承相结合,以“山水相融、田园相映、林城相依、知音文化”为指导思想,打造韵律田园风光、雅乐知音故事、静谧莲花水乡三大主题;形成隔离系统、绿化系统、慢行系统、标识系统、服务系统五大系统,具备湖泊修复、生态保护、休闲游憩、旅游经济四大功能。绿道规划兴建Ⅰ级驿站24个、Ⅱ级驿站48个、自行车道110千米、人行步道60千米、游艇码头10座。
高山流水、夜泊枫桥、雨打芭蕉、渔舟唱晚等24个诗意景点。
沿湖周边的羊谷山、虎头山、马鞍山、龙头山等形成“十二生肖”系列。