
1. 确定坏磁盘对应的SN编号、OSD编号和Linux系统识别编号。
第一种方法:批量化使用smartctl命令检测CEPH系统中机械硬盘的信息,确定有坏道磁盘的SN编号,或留取正常磁盘的SN编号。
第二种方法:在CEPH网页管理界面的OSD栏目中搜索关键词down,检测对应OSD的编号、磁盘SN编号和磁盘在Linux系统中的识别名称,如下图所示。
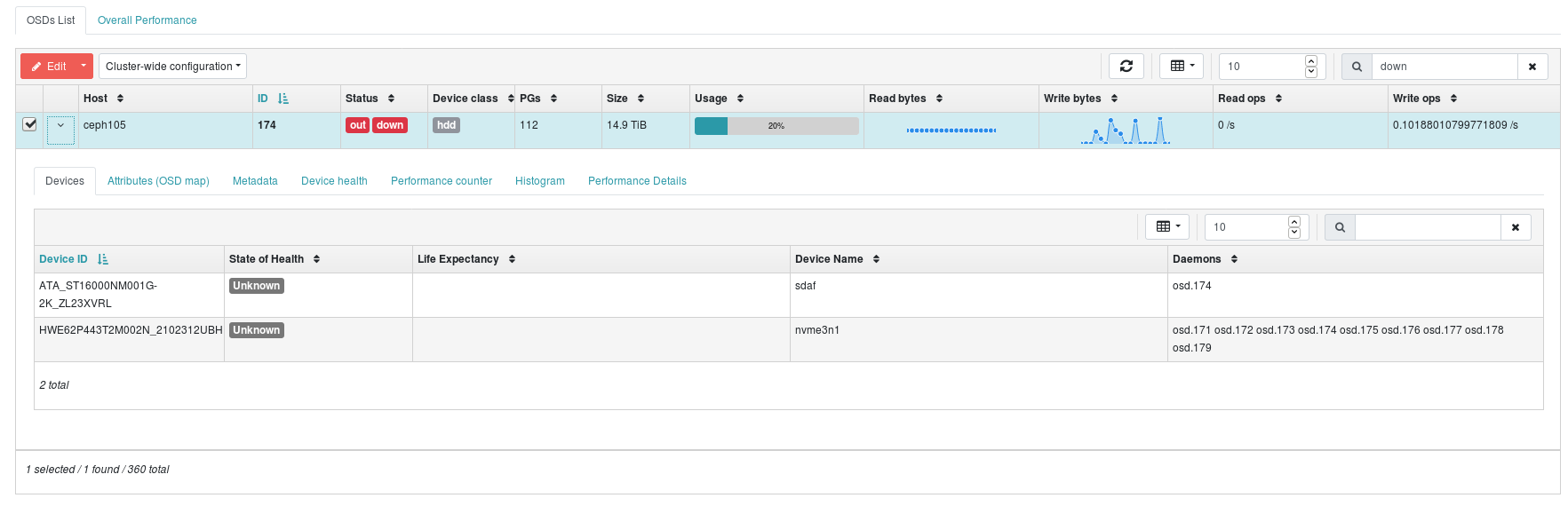
以上示例中找到的损坏磁盘关键信息:
磁盘对应的OSD编号:osd.174 后续需要删除并重建该osd编号。 磁盘SN编号:ZL23XVRL 有利于拔下有问题的硬盘,以免拔错。 Linux下的磁盘识别名称:sdaf 加上新盘后,需要对该盘进行分区操作。
2. 关停CEPH系统,关闭CEPH存储服务器,跟换坏磁盘,重启CEPH存储服务器
在计算服务器上卸载CEPH文件系统(可选)。我这边由于需要通过一台登录节点服务器作为中转,再登录CEPH服务器进行操作。因此,该登录节点服务器需要卸载 CEPH文件系统,以免CEPH文件系统掉线后,无法登录该服务器。
for i in 1 2 11 12 13 14 15 16 17 18 19 20
do
echo "ssh node$i sudo umount -l /ceph"
done > command.umount.list
ParaFly -c command.umount.list -CPU 12
通过指令暂停CEPH系统:
ceph osd set noout
ceph osd set norecover
ceph osd set norebalance
ceph osd set nobackfill
ceph osd set nodown
ceph osd set pause
再关闭所有CEPH服务器或仅关闭有坏道的CEPH存储服务器的Linux系统。本次是在ceph105机器上发现有坏盘,对该机器关机并更换硬盘后手动启动,其它存储服务器重启。
echo "ssh ceph110 sudo shutdown -r now
ssh ceph109 sudo shutdown -r now
ssh ceph108 sudo shutdown -r now
ssh ceph107 sudo shutdown -r now
ssh ceph106 sudo shutdown -r now
ssh ceph105 sudo shutdown -h now
ssh ceph104 sudo shutdown -r now
ssh ceph103 sudo shutdown -r now
ssh ceph102 sudo shutdown -r now" > command.shutdown.list
ParaFly -c command.shutdown.list -CPU 9
ssh ceph101 sudo shutdown -r now重启CEPH集群后,进行时间同步、网络优化和CEPH参数优化。
for ((i=102;i<=110;i=i+1))
do
echo "ssh ceph$i ntpdate ceph101"
done > command.ntpdate.list
ParaFly -c command.ntpdate.list -CPU 9
for ((i=102;i<=110;i=i+1))
do
echo "ssh ceph$i systemctl restart chronyd.service"
done > command.chronyd.list
ParaFly -c command.chronyd.list -CPU 9
for ((i=102;i<=110;i=i+1))
do
echo "ssh ceph$i /root/bin/rc.local"
done > command.rc_local.list
ParaFly -c command.rc_local.list -CPU 9
/root/bin/rc.local
for ((i=102;i<=110;i=i+1))
do
echo "ssh ceph$i /root/bin/ethtool_lro.sh"
done > command.ethtool_lro.list
ParaFly -c command.ethtool_lro.list -CPU 9
/root/bin/ethtool_lro.sh
for ((i=102;i<=110;i=i+1))
do
echo "ssh ceph$i /root/bin/test.sh"
done > command.ethtool_test.list
ParaFly -c command.ethtool_test.list -CPU 9
/root/bin/test.sh
for ((i=101;i<=110;i=i+1))
do
echo "ssh ceph$i /root/bin/modifing_OSD_parameters.pl 22 8 true 10 86400 604800 0.5 0.05 259200 100 10 10 100"
done > command.modifing_OSD_parameters.list
ParaFly -c command.modifing_OSD_parameters.list -CPU 10
ceph config set mds mds_log_max_segments 1024
ceph config set mds mds_cache_trim_threshold 25600000
ceph config set mds mds_cache_trim_decay_rate 0.01
ceph config dump
取消CEPH系统的暂停操作:
ceph osd set noout
ceph osd set norecover
ceph osd set norebalance
ceph osd set nobackfill
ceph osd set nodown
ceph osd set pause
给CEPH存储服务器添加虚拟内存(可选)。我管理的CEPH存储服务器每个节点内存为256 GiB,在MDS服务器上可能不够,给每台服务器再添加256G SWAP空间。
for ((i=101;i<=110;i=i+1))
do
echo "ssh ceph$i swapon /swapadd"
done > command.swapon.list
ParaFly -c command.swapon.list -CPU 10
3. 对新加入的磁盘进行分区操作
在更换了坏盘的ceph105主机上进行新盘的分区操作。
根据最开始安装CEPH系统时留下的磁盘分区的操作记录信息,对新加入的磁盘进行相同的分区操作。首先,使用新加入的磁盘,添加到一个新的虚拟盘中。
vgcreate ceph-block-31 /dev/sdaf然后,对虚拟盘进行分区。
lvcreate -l 100%FREE -n block-31 ceph-block-31以上命令需要确定新加入磁盘对应的Linux识别编号和虚拟盘编号,是操作的成败关键。
由于新加入的盘替换了坏盘的位置,重启服务器后,其Linux识别编号不变。若采用不关停CEPH系统直接更换硬盘的话,则热插拔更换硬盘后,其Linux识别编号在所有磁盘识别编号往后计数,和坏盘之前的编号不一致。
由于最初安装CEPH系统时,直接使用了ceph-block-num的虚拟盘分区名称。若此时未保留最初的磁盘分区命令,可以使用lvdisplay查看系统中的虚拟盘分区(也称为逻辑卷)信息,查看缺失的逻辑卷名称。
lvdisplay | grep " LV Name" | grep block | sort
lvdisplay | grep " VG Name" | grep block | sort4. 删除并重建OSD
删除OSD编号:
ceph auth del osd.174
ceph osd crush remove osd.174
ceph osd rm 174根据最开始安装CEPH系统时留下的OSD创建记录,将新的虚拟盘分区创建成OSD。由于使用了bluestore的方法,一个OSD包含一个完整物理磁盘做的逻辑卷和一块固态硬盘部分扇区做的逻辑卷。后者的逻辑卷名称不能搞错,因此该步骤一定要有最初安装CEPH系统时留下的OSD创建记录。
ceph-volume lvm create --bluestore --data ceph-block-31/block-31 --block.db ceph-db-4/db-31以上步骤会自动分配一个新的OSD编号。CEPH系统应该是自动按照数字编号往后进行OSD编号分配。由于刚删除了一个编号,新的自动分配的编号就刚好是删除的OSD编号。
新的OSD上线后,数据会自动进行重新分配(rebalancing),结束后CEPH恢复健康状态。
[root@ceph101 ~]# ceph -s
cluster:
id: 8f1c1f24-59b1-11eb-aeb6-f4b78d05bf17
health: HEALTH_WARN
Slow OSD heartbeats on back (longest 23249.475ms)
Slow OSD heartbeats on front (longest 23245.394ms)
services:
mon: 5 daemons, quorum ceph101,ceph103,ceph107,ceph109,ceph105 (age 21m)
mgr: ceph107.gtrmmh(active, since 22m), standbys: ceph101.qpghiy
mds: cephfs:3 {0=cephfs.ceph108.iuobhj=up:active,1=cephfs.ceph102.imxzno=up:active,2=cephfs.ceph104.zhkcjt=up:active} 1 up:standby
osd: 360 osds: 360 up (since 17m), 360 in (since 17m); 47 remapped pgs
data:
pools: 4 pools, 10273 pgs
objects: 386.82M objects, 657 TiB
usage: 1.2 PiB used, 4.0 PiB / 5.2 PiB avail
pgs: 8742316/3849861458 objects misplaced (0.227%)
10220 active+clean
47 active+remapped+backfilling
6 active+clean+scrubbing+deep
io:
client: 3.4 MiB/s rd, 392 MiB/s wr, 6 op/s rd, 221 op/s wr
recovery: 181 MiB/s, 103 objects/s
progress:
Rebalancing after osd.174 marked in (17m)
[=======.....................] (remaining: 44m)